Producer Consumer example using GHCJS and NixOS
April 13, 2015
For a time I have wanted to try GHCJS, but it was rumored to be hard to install. However, as I recently installed NixOS on my desktop computer and it has packages for GHCJS, I decided I would give GHCJS a shot. Bas van Diijk had made a mailing list post outlining how he uses uses GHCJS with NixOS. However, being new to NixOS and the Nix package manager language, I had a hard time understanding Bas van Diijk’s post. But with time and a lot of errors, I got a working setup. In this post I will describe what I did.
If you want to follow this howto, you properly already have NixOS installed. If not, you can find a good guide in the Nix Manual. If you want to install NixOS in a virtual machine this guide will help you.
Our example will depend on the unstable Nix package repository. Therefore do:
> mkdir ProducerConsumer > cd ProducerConsumer > git clone https://github.com/NixOS/nixpkgs.git
Unfortunately, I could not get the code to work with the newest version of Nix unstable. This is not necessarily surprising as unstable is a moving and not always perfectly working target – hence the name. But here the Nix way comes to the rescue, as one can just roll back the Nix Git repository back to when it did work:
> cd nixpkgs > git reset --hard 1901f3fe77d24c0eef00f73f73c176fae3bcb44e > cd ..
So with Nix you can easily follow the bleeding edge, without getting traped in a non-working unstable branch. I would not know how to do this easily with my former Linux distribution Debian.
We will start creating the client:
> mkdir client > mkdir client/src
We need a client/default.nix file descriping how to buld this client:
{ pkgs ? (import <nixpkgs> {})
, hp ? pkgs.haskellPackages_ghcjs # use ghcjs packages instead of ghc packages
}:
hp.cabal.mkDerivation (self: {
pname = "ProducerConsumerClient";
version = "1.0.0";
src = ./.;
isLibrary = false;
isExecutable = true;
buildDepends = [ hp.ghcjsDom hp.random hp.stm ];
buildTools = [ hp.cabalInstall ];
})
This is fairly standard default.nix for Haskell projects, except that we are using GHCJS instead of GHC. If you’re not familiar with Nix expressions, then a good guide can be found here.
We also need a Cabal file client/ProducerConsumerClient.cabal:
name: ProducerConsumerClient
version: 1.0.0
author: Mads Lindstrøm
build-type: Simple
cabal-version: >=1.10
executable producer-consumer-client
main-is: Main.hs
build-depends: base >=4.7 && <4.8,
ghcjs-dom >= 0.1.1.3,
random >= 1.0.1.3,
stm >= 2.4.2
hs-source-dirs: src
default-language: Haskell2010
Finally we need to actually program. We create a small example with a producer and consumer of integers. And a showNumbersVar function, which presents the numbers to the user. We only have one source file client/src/Main.hs:
module Main (
main
) where
import GHCJS.DOM
import GHCJS.DOM.Document
import GHCJS.DOM.HTMLElement
import System.Random (randomRIO)
import Control.Concurrent.STM (TVar, retry, atomically, modifyTVar, readTVar, newTVar)
import Control.Concurrent (threadDelay, forkIO)
main :: IO ()
main = do
numbersVar <- atomically $ newTVar [1, 2, 3]
forkIO (producer numbersVar)
forkIO (consumer numbersVar)
showNumbersVar [] numbersVar
showNumbersVar :: [Int] -> TVar [Int] -> IO ()
showNumbersVar lastNumbers numbersVar = do
currentNumbers <- atomically (do numbers <- readTVar numbersVar
if lastNumbers == numbers then retry else return numbers
)
Just doc <- currentDocument
Just body <- documentGetBody doc
htmlElementSetInnerHTML body ("<h1>" ++ unlines (map (\x -> show x ++ "<br>") currentNumbers) ++ "</h1>")
showNumbersVar currentNumbers numbersVar
producer :: TVar [Int] -> IO ()
producer numbersVar = do
sleepMillies 500 2000
newNumber <- randomRIO (0, 100)
atomically (modifyTVar numbersVar (newNumber:))
producer numbersVar
consumer :: TVar [Int] -> IO ()
consumer numbersVar = do
sleepMillies 500 2000
atomically (modifyTVar numbersVar (drop 1))
consumer numbersVar
sleepMillies :: Int -> Int -> IO()
sleepMillies minMs maxMs = randomRIO (minMs*1000, maxMs*1000) >>= threadDelay
This is ordinary Haskell and the code should not have many surprises for the experienced Haskell programmer. It is very nice that we can use Software Transactional Memory (STM) to handle integer list. STM is likely to be especially helpful in a user interface application, where there necessarily is a lot of concurrency.
We can build the client now:
> nix-build -I . client
If successful you should get a link called result, which points to the ProducerConsumerClient in the Nix store. Try:
> ls -l result/bin/producer-consumer-client.jsexe/
Where you should see some files including javascript and html files.
Next the server part. The server parts needs access to the client. We can achieve this by creating a Nix expression pointing to both client and server. Create packages.nix:
{ pkgs ? import <nixpkgs> {} }:
rec {
client = import ./client { };
server = import ./server { inherit client; };
}
The server will be a simple Snap application, which just serves the JavaScript files created by ProducerConsumerClient.
We need a server directory:
> mkdir server > mkdir server/src
And server/default.nix:
{ pkgs ? (import <nixpkgs> {})
, hp ? pkgs.haskellPackages_ghc784
, client
}:
hp.cabal.mkDerivation (self: {
pname = "ProducerConsumerServer";
version = "1.0.0";
src = ./.;
enableSplitObjs = false;
buildTools = [ hp.cabalInstall ];
isExecutable = true;
isLibrary = false;
buildDepends = [
hp.MonadCatchIOTransformers hp.mtl hp.snapCore hp.snapServer hp.split hp.systemFilepath
client
];
extraLibs = [ ];
preConfigure = ''
rm -rf dist
'';
postInstall = ''
# This is properly not completely kosher, but it works.
cp -r $client/bin/producer-consumer-client.jsexe $out/javascript
'';
inherit client;
})
And server/ProducerConsumerServer.cabal:
Name: ProducerConsumerServer
Version: 1.0
Author: Author
Category: Web
Build-type: Simple
Cabal-version: >=1.2
Executable producer-consumer-server
hs-source-dirs: src
main-is: Main.hs
Build-depends:
base >= 4 && < 5,
bytestring >= 0.9.1 && < 0.11,
MonadCatchIO-transformers >= 0.2.1 && < 0.4,
mtl >= 2 && < 3,
snap-core >= 0.9 && < 0.10,
snap-server >= 0.9 && < 0.10,
split >= 0.2.2,
system-filepath >= 0.4.13,
filepath >= 1.3.0.2
ghc-options: -threaded -Wall -fwarn-tabs -funbox-strict-fields -O2
-fno-warn-unused-do-bind
And server/src/Main.hs:
{-# LANGUAGE OverloadedStrings #-}
module Main where
import Prelude hiding (head, id, div)
import qualified Prelude
import Snap.Core (Snap, dir, modifyResponse, addHeader)
import Snap.Util.FileServe (serveDirectory)
import Snap.Http.Server (quickHttpServe)
import System.Environment (getEnvironment, getEnv, getExecutablePath)
import System.FilePath
import Data.List.Split (splitOn)
import Data.List (isInfixOf)
main :: IO ()
main = do
exePath <- getExecutablePath
let baseDir = takeDirectory exePath ++ "/../javascript/"
quickHttpServe $ site baseDir
getClientDir :: IO String
getClientDir = do
getEnvironment >>= mapM_ print
nativeBuildInputs <- getEnv "propagatedNativeBuildInputs"
return $ Prelude.head $ filter (isInfixOf "my-test-app") $ splitOn " " nativeBuildInputs
site :: String -> Snap ()
site clientDir =
do Snap.Core.dir "client" (serveDirectory clientDir)
let header key value = modifyResponse (addHeader key value)
header "Cache-Control" "no-cache, no-store, must-revalidate"
header "Pragma" "no-cache"
header "Expires" "0"
Now we can compile the client, using packages.nix, and the server:
> nix-build -I . packages.nix -A client > nix-build -I . packages.nix -A server
Now it is time to run the application:
> result/bin/producer-consumer-server
and point your browser to http://localhost:8000/client. You should see the numbers one, two, and three. After about a second you should see the numbers lists changing, as the producer and consumer changes the list.
Debian’s Quality Problems
June 13, 2011
For the last 8-10 years I have been using Debian. And when Debian Squeeze came out I happily upgraded. The upgrade went fine, but using Squeeze has been very annoying. The quality has been abysmal, and not at all what I have come to expect of Debian.
My main complaint is the Gnome experience. Epiphany, which I used to be quite happy with, crashed a lot and Gnome recommended Iceweasel anyway. Iceweasel do not have the nice bookmark system of Epiphany, but it works well. But I was annoyed of having to deal with the buggy Epiphany.
My earlier chat client, Pidgin, did not work very well in Squeeze either, so I decided to try Empathy. After some tweaking, looking though bug reports, I got Empathy working all right. The sound is still not working, which is annoying, but you can live without sound in a chat client. Also, Empathy sometimes do not login to MSN and Google Talk when starting the computer. Restarting Empathy fixes the login problem, but it is quite annoying. Something so common as a chat client needs to work out of the box. No tweaking.
Today, I needed to use my Evolution calendar for the first time. Every time I try to save an appointment, Evolution says “The name :1.164 was not provided by any .service files”, and “The Evolution calendar has quit unexpectedly … Your calendars will not be available until Evolution is restarted”. Again, something common, like the standard Gnome calendar, needs to work without any fuzz. I tried googling, but that did not help much. Anyway, I am tied of tweaking.
What's more, I have seen a couple of kernel panics in a couple of month. This is quite unusual for a Debian system. I suspect that it might be related to running a Xen kernel, but I do not really know.
I guess I am just fed up, and I have started to consider something besides Debian. Linux still got a lot going for it, but the Debian version of Gnome do not seem to be part of it. I still feel “at home” when using Gnome. I think the at-home feeling stems from Gnome’s nice and simply design, but that is not enough when core applications is so much hassle.
Random Thoughts form Øredev 2010
November 14, 2010
Last week I was at the Øredev 2010 conference and it was the first IT conference I have attended. I have, however, attended a wastewater conference around 2005, but that still leaves me little to compare Øredev to.
Monday I attended an all-day seminar on REST, which I found to be quite interesting, even if I left feeling a little confused. The two presenters, Jim Webber and Ian Robinson, were good and have written the book “REST in Practice”, which I will properly buy (and yes, I got a discount ticket :) ).
I worked on Thursday, as this conference day did not look particular interesting. I will not go into all the presentations I attended, but will say I few words about the most interesting ones.
Giorgio Sardo from Microsoft did the talk “Deep Dive into HTML5”, where here presented HTML 5 in general and Microsoft’s HTML 5 work in particular. He did some live coding, which worked out really well. I am, however, concerned about HTML 5, as it seems extraordinary complex. The map of HTML 5 may give you an idea – if you like me, don’t have Silverlight, then look at the picture. Each box in the picture is a standard, which is part of HTML 5 and thus leaves room for specification errors and implementation errors by vendors. I just cannot see have such a huge set of specs can ever be implemented without gigantic headaches for implementors as well as users. Granted, I am taking the 5-minute 12 kilometer view – but still, color me skeptical.
Simultaneously with the HTML 5 talk, Jonas Bonér did a talk about Akka, which is a concurrency framework for Scala. Jonas is a good presenter and has made what seems (never tried it) a nice piece of technology. But a half year ago, I saw him make a two hour presentation of Akka, and thus saw no point in attending this one hour talk.
Later Wednesday, I attended the talk “Robotium Testing for Android” by Hugo Josefson and Renas Reda. About a week before the conference, I had started using Robotium myself and it is really nice. Furthermore, the vanilla Android testing API just sucks, as better explained in this blog post over at Brain Flush.
Thursday, Sean Cribbs talked about Webmachine, which is a quite novel HTTP implementation. The main selling point, is that it leaves a large degree of control in the hands of the Webmachine user (a programmer). Webmachine also has a very cool debugging tool, where you can see a flow diagram of a HTTP response process and what happened at each step. Webmachine is intended to be used for REST applications, where more fine grained control of HTTP may be needed. Very nice. Webmachine is implemented in Erlang.
Marcus Lagergren and Marcus Hirt presented the JRocket JVM Friday. They managed to give a good feel for the implementation of an adaptive JVM, in just an hour, which is quite impressive. They also showed some very nice debugging tools they were working on.
All in all, the conference was a nice experience. However, there were a few bad things as well. First of all, too many of the talks had nothing to say or talked without really getting to any points. I think part of the problem, was that I could have selected the talks to go to better – better planing I guess. I was half-sick Wednesday though Friday, so I was not motivated to investigate the different speakers and Øredev did not make it easy. It would have been really great, if Øredev had the speakers slides online, so that one could have had a better idea about what a speaker would say.
On a final note, I was disappointed about the food and the physical environment. Some rooms were quite cold and the noise level from talks “next door” were often annoyingly laud. From other attendees, I got the clear impression that Øredev had better food and as good rooms as other IT conferences, thus it is properly just me who has been spoiled by a wastewater conference, where the food and rooms were exceptionally good.
My First Android Application
August 6, 2010
I recently bought a HTC Desire Android phone. Giving my previous phone, Nokia 3310, it was like going from a horse drawn carriage to a Ducati motorcycle. Android phones lets you install new phone applications from the Android market, and you can even program your own applications in Java. Professionally, I am working as a Java programmer, and therefore wanted to roll my own Android application.
But before you can program, you need to setup your development environment. Android is married to the Eclipse IDE and thus I tried to get an Eclipse + Android SDK up and running. It was not quite as easy as “apt-get install XXX”, as I can usually do on my Debian machine, but it was not too bad either. Especially this howto trailered for Debian users was a godsend. The Eclipse setup is integrated nicely with the Android Emulator. Especially the turn-around time from making a change in ones program and seeing it run in the emulator is short and easy, just press Ctrl-F11 and the application run in the emulator shortly after. I was a bit uneasy about this setup as, in my experience, “overachieving” IDEs usually ends up being more trouble than it is worth. But the Eclipse + Android SDK has so far worked quite nicely.
At work I spend a lot of time waiting – waiting for the computer to compile, waiting to launch the application we are working on, waiting to … Basically, we need faster machines. To make a stronger case for this, I wanted to measure how much time I wasted waiting. Thus, I created a small application to measure wasted time. The application has one button which, when pressed, triggers a timer. When the button is pressed again the timer is stopped, and the current time + the length (in seconds) of the measurement is stored to disc and displayed on-screen. The cycle then repeats, when you press the button the third time it will again start a timer, …

The application architecture is quite simple, only containing four classes and one interface. The MeasurementGUI class updates the Timer class (the model). The Timer class sits in the middle and informs the MeasurementGUI of state changes, and asks the Storage class to store the measurements on disc. When the MeasurementGUI class is notified of state changes, it queries the Timer class (the model) for the current state.

After developing this application, I must say that the Android development experience is quite nice. The Eclipse setup worked well and the documentation is good. Developer.android.com provides both reference style (Javadoc API documentation) and small articles. However, usually I just google for what I need, and sometimes end up on developer.android.com, other times on other websites.
The one thing I found annoying, was the strong XML focus of the Android SDK. I should properly have expected this as most Java programmers have a strong love for XML. When developing for android, GUI layout is specified using XML files, as it is more declarative according to the creates of the Android API. And it does make GUI construction more declarative, but only for GUI layout and only when you know which widgets, how many, and where to place widgets at compile time. The flip side to using XML for layout is:
- That XML is overly verbose and Android XML is even more verbose than it needs to be.
- You need to program in two languages – Java and XML.
- When you want to manipulate some widget, e.g. changing a button label, you need to extract the button from “the system” and cast it to a Button type. And casting just sucks… or at least it should be avoided.
Fortunately, you are not forced to use XML for layout. For example, my own application uses no XML for layout. The only trouble is that many Android howtos, do use XML for layout, so you need to translate to a non-XML world.
That said, I enjoined developing for Android and it is defiantly not the last Android application I develop.
Update 2010/08/07: You can download the application source code here.
ISO/Ansi Standards, Copyright and SQL
July 4, 2009
Imagine the perfect ISO/Ansi standard for a programming language. It would be concise, precise, 100% correct and writen in a formal language. Imagine constructing software that would implement a parser for the programming langauge. You could simply open the standard at page one and mechanically translate it to your favorite programming language. One could even construct a computer program to automate the translation from standard into working parser code. In fact, using a computer program to translate the standard would be best, as it would minimize work and minimize the chance of errors.
Except… except that ISO/Ansi standards are copyrighted and a translation would make your implementation a derivative work, at least as I read the law US Code Title 17:
A “derivative work” is a work based upon one or more preexisting works, such as a translation, musical arrangement, dramatization, fictionalization, motion picture version, sound recording, art reproduction, abridgment, condensation, or any other form in which a work may be recast, transformed, or adapted. A work consisting of editorial revisions, annotations, elaborations, or other modifications which, as a whole, represent an original work of authorship, is a “derivative work”. (the bold-font is my own)
So what is the point of having a technology standard, if implementors cannot use it, because it is copyrighted?
Some may argue, that no standard is perfect and large parts of standards are described as English prose, as opposed to formal language. So my assumption is invalid and therefore my argument is invalid too. Well true, no standard is perfect, but parts of many standards are written in a concise, precise and formal language. And the formal part could be translated (automatically) to a working implementation. Except when the formal part is copyrighted…
Others may argue, that standard organizations too have expenses, and thus they need to charge for their standards. Again true, but what is the point of the standard in the first place, if one cannot use the standard directly to construct technology ? Second, everything do not have to be free of charge. The informal English prose could be copyrighted. And the standards organization could include a license explicitly granting the right to translate the English prose into a working implementation and leave the formal part in the public domain. Third, they could look for other streams of revenue, like certifying software and individuals.
I am not a lawyer, and thus I am hopeful, that I misunderstand the law or that I overlooking some crucial detail. Please comment if I am. Other comments are also welcome.
You may wonder, why the rant? I recently considered implementing a SQL parser and considered translating the formal (BNF) part of the ISO/Ansi SQL standard automatically, but this let me to consider copyright, which let me to this post.
WxGeneric 0.6.0
May 8, 2009
I am happy to announce release 0.6.0 of WxGeneric. There is plenty of
changes, as it has been 6 months since the last release:
- Better handling of events
- Better layout of widgets
- Fixed alignment of labels -bug
- Composite implements more wxHaskell interfaces
- Code cleanups
- Documentation
- Added two-column layout
- Added smart layout (chooses two-column when size of windows > 400 pixels)
- More user-customisation possibilities
- Automatic shortcuts
Using Mutable Arrays for Faster Sorting
February 19, 2009
Various people have tried improving the Data.List.sort function in Haskell, see Data.List.sort, not so good? and Sorting At Speed. In this post, I will also attempt improving sort performance. I will use a simple algorithm:

Mergesort with Mutable Arrays
Below we will see why converting a linked list to an array improves sorting performance.
Linked lists versus mutable arrays
I have depicted a linked list graphically below. Data constructors are shown as boxes, pointers as arrows, and elements as ellipses. As seen we need two pointers for each element. As Haskell’s linked lists are immutable we must recreate the list if we want to change one or more elements.

A Singly Linked List
A Haskell mutable array is depicted below. We only use one pointer per element and the lookup operation and the update operation are both O(1).

An Array
Mergesort
Mergesort for immutable linked lists reallocates (recreates) a new list for each traversal. That is, it recreates the list for each time it has visited all elements once. There are log(n) traversals. All these memory allocations and latter cleanups by the garbage collector takes time. See Sorting At Speed for GHC’s implementation of mergesort.
Mergesort, using mutable arrays, do not need to recreate the list for each traversal. It uses two list operations, update and lookup, which are both O(1). Like mergesort for immutable linked lists, mergesort for mutable arrays still needs to traverse the list log(n) times.
The use of one pointer per element and no need to reallocate the list for each traversal, makes it seem likely that converting a linked list to a mutable array, sorting and converting back again, may be faster than sorting a linked list directly.
Benchmarks
Up until now it has all been theory and I will need to do measurements to back up the claim, that we can sort faster by converting to a mutable array. I do not know all the idiosyncrasies of modern hardware or which optimizations GHC may or may not do. There may be GHC optimizations, which makes immutable linked lists a lot faster than I imagine.
I have therefore implemented a mergesort using mutable arrays. I have used this program to benchmark my implementation. The program was compiled with GHC 6.10.1 using the optimization flag -O2. And I ran the benchmark program as: “./Benchmark +RTS -K32388608 -RTS >/dev/null”. I have tested both with lists of Ints and list of strings.
The benchmark program calls System.Mem.performGC before and after sorting. The last call to System.Mem.performGC is measured as part of the sorting. In this way I am internalizing the cost of garbage collection into the sort function. I use this in stead of measuring memory use directly. The the first call is done, so that we start with a clean sheet before each measurement.
| Iterations | Number of elements | Data.List.sort (ms) | Array sort (ms) | Speedup (%) |
|---|---|---|---|---|
| 25000 | 10 | 264 | 272 | -4 |
| 50000 | 10 | 684 | 572 | 16 |
| 100000 | 10 | 2396 | 2216 | 7 |
| 25000 | 20 | 1136 | 1056 | 7 |
| 10000 | 40 | 916 | 808 | 11 |
| 10000 | 50 | 1184 | 1016 | 14 |
| 10000 | 75 | 1872 | 1548 | 17 |
| 5000 | 100 | 1288 | 1048 | 18 |
| 5000 | 200 | 2912 | 2420 | 16 |
| 2000 | 400 | 2492 | 2024 | 18 |
| 2000 | 600 | 4000 | 3184 | 20 |
| 2000 | 800 | 5624 | 4276 | 23 |
| 1000 | 1000 | 3656 | 2744 | 24 |
| 20 | 10000 | 2276 | 1592 | 30 |
| 5 | 100000 | 8844 | 4260 | 51 |
| 2 | 1000000 | 62559 | 24677 | 60 |
| Iterations | Number of elements | Data.List.sort (ms) | Array sort (ms) | Speedup (%) |
|---|---|---|---|---|
| 10000 | 10 | 304 | 312 | -3 |
| 20000 | 10 | 604 | 624 | -4 |
| 40000 | 10 | 1216 | 1252 | -3 |
| 10000 | 20 | 524 | 504 | 3 |
| 5000 | 50 | 632 | 544 | 13 |
| 5000 | 100 | 1320 | 1072 | 18 |
| 2000 | 200 | 1156 | 980 | 15 |
| 1000 | 400 | 1236 | 1008 | 18 |
| 750 | 600 | 1504 | 1184 | 21 |
| 500 | 800 | 1404 | 1080 | 23 |
| 500 | 1000 | 1828 | 1404 | 23 |
| 10 | 10000 | 992 | 716 | 27 |
| 5 | 100000 | 8860 | 4296 | 51 |
As can be seen, the speedups for large lists are quite good, but not for small lists. The speedup is even slighty negative for some small lists. That the benefits are better for large lists is not surprising, when considering that the cost of converting to and from arrays is O(n), whereas the gains are O(n * log(n)).
Sorting Ints shows better speedup than sorting strings. I speculate, that this is due to strings being more expensive to compare than Ints. As both Data.List.sort and my own sorting algorithm uses the same number of comparisons, the actual compare operations are equally expensive for both algorithms. When a constant part, the compare operations, is larger, then the (percentage) speedup gets smaller.
Taking the beauty out of functional programming?
Some might argue that using mutable arrays removes the beauty from functional programming – and they would be right. I do not see a problem though, as the nasty mutable code can be hidden behind a nice functional interface. Furthermore, a sorting algorithm only needs to be implemented once, but can be used man times.
Future Improvements
Although my sorting algorithm is, in most cases, faster than the stock GHC one, there is still room for improvement.
As shown, we are converting a linked list to an array, and back to a linked list again. As we are converting to an array, we might as well convert to an array of unboxed types in stead. Using unboxed types would avoid one pointer per element. Initial experiments shows significant speedups, as compared to my current sorting algorithm. Of cause, this only works for types which can be unboxed, which fortunately includes popular types such as Int, Double and Float. Using rewrite rules we can even hide the choice of using unboxed types from the user of the sorting algorithm.
Haskell has other types of arrays, such as Parallel arrays (module GHC.PArr) which is claimed to be fast. Choosing another array implementations may improve sorting performance.
Lastly, as Don Stewart explains in his blogpost “A Journal of Haskell Programming Write Haskell as fast as C: exploiting strictness, laziness and recursion” we may use GHC core to gain better performance.
Overlapping Instances in Haskell
September 27, 2008
In an earlier post I proposed adding composition to wxHaskell. In a effort to make the composites seem as much like wxHaskell widgets as possible, some type classes were instantiated automatically and some could be “inherited” with a little extra work. Unfortunately, the latter kind proved to be problematic. They are given this type of instance declarations:
instance Checkable super => Checkable (Composite super user) where
checkable = mapFromSuper checkable
checked = mapFromSuper checked
which says that if the super-type (see blogpost for details) implements Checkable, then so do the composite.
But what if you do not want the default implementation of Checkable, but want to roll your own? You are our of luck, as Haskell compilers will complain about overlapping instances. Even if the super-type do not implement Checkable, then compilers will still complain as contexts (everything before “=>” in the example above) will not influence the judgment of whether instances are overlapping. This fact is also described in the GHC manual:
When matching, GHC takes no account of the context of the instance declaration (context1 etc). GHC’s default behaviour is that exactly one instance must match the constraint it is trying to resolve.
This should not have been a surprise for me. Especially, as I have made a similar mistake before. Nonetheless, I somehow find it intuitive that a Haskell compiler would take contexts into consideration when deciding type classes, but they do not.
As a sidenote, I think the terms “inherited”, “super” and “user” was properly not a wice choice of words. But I made it in the original proposal, and I will keep it for now to avoid further confusion.
Solution to our Predicament
To avoid the problem described above, we have decided to remove the super type from the Composite type, which leaves just one type variable for the Composite type. To still handle inheritance of type classes we introduce a new type:
newtype Inherit super = Inherit { inherit :: super }
and instances like:
instance Checkable super => Checkable (Composite (Inherit super)) where
checkable = mapInheritedAttr checkable
checked = mapInheritedAttr checked
mapInheritedEvent :: Event super event -> Event (CompositeInherit super) event
mapInheritedEvent event = mapEventF (inherit . pickUser) event
That is, we use the Inherit type as a marker type, like Java uses marker interfaces, to indicate that we want to inherit (or automatically derive) additional instances.
In this way, we avoid overlapping interfaces, keep the existing flexibility and even makes life a little simpler for people not inheriting instances, as they must now deal with only one type parameter to the Composite type.
MetaHDBC paper (draft)
September 18, 2008
In May I started a Haskell-cafe discussions, where I proposed using
Template Haskell to do type-safe database access. The idea got well
received and turned into the MetaHDBC library.
Concurrently with development I also wrote a paper describing
MetaHDBC. I have never writing a paper before, and I therefore tried
to imitate the best by following Simon PJ’s slides and video about
writing papers.
A draft of the paper can be found here. Your opportunity to
influence the paper is large, as my limited paper-writing experience
means I have little preconception about what a good paper looks
like. I would especially like comments about the overall quality of
the paper, can it be called scientific and comments about anything I
could do to improve the paper. And remember, if commenting, honest is
better than polite.
Using WxGeneric
May 21, 2008
As I posted earlier AutoForms has been reimplement in a new library called WxGeneric. In this post we look at using WxGeneric from a purely practical perspective.
To understand this post you should already be familiar with Haskell and WxHaskell.
The short introduction to WxGeneric is that it is a library to generically construct WxHaskell widgets, by looking at the structure and names of types. If you want more background information, you should look at AutoForms, which is the library WxGeneric is based upon.
Installation
Before installing WxGeneric you must install the following dependencies:
The hard to install dependencies are GHC and WxHaskell (both of which you properly already got). The rest are installed as ordinary cabalized packages. See here for general information about installing cabalized packages.
Next download and install WxGeneric like a normal cabalized package.
Tuple example
We will start with a small example which converts a tuple (Int, String, Double) into a WxHaskell widget. Below you can see the example code. The code which is WxGeneric specific are italicized. The rest is ordinary WxHaskell code. The most interesting new function is genericWidget, which is used to construct widgets generically. This function takes two parameters – a frame and the value to turn into a widget. Also we have a new attribute called widgetValue, which can be used to get and set the value of a widget. The rest of the code is ordinary WxHaskell code:
module TupleExample where
import Graphics.UI.WxGeneric
import Graphics.UI.WX
main :: IO ()
main = start $
do f <- frame [ text := "Tuple Example" ]
p <- panel f []
en <- genericWidget p (3 :: Int, "Hans", 5.5 :: Double)
b <- button p [ text := "&Print tuple"
, on command := get en widgetValue >>= print ]
set f [ layout := container p $ row 10 [ widget en, widget b ] ]
And the resulting GUI:
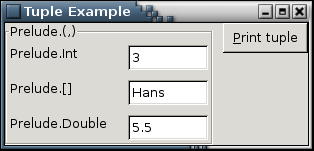
Alarm example
In this example we will see how to convert a programmer defined data type into a widget. We have chosen an Alarm data type, which contains an alarm name and time of day (measured in minutes). The code:
{-# LANGUAGE FlexibleInstances, MultiParamTypeClasses
, TemplateHaskell, UndecidableInstances #-}
module Alarm where
import Graphics.UI.WxGeneric
import Graphics.UI.SybWidget.MySYB
import Graphics.UI.WX
import Graphics.UI.WXCore
data Minutes = Minutes Int deriving (Show, Eq)
data Alarm = Alarm { name :: String
, timeOfDay :: Minutes
} deriving (Show, Eq)
$(derive [''Minutes,''Alarm])
instance WxGen Alarm
instance WxGen Minutes
main :: IO ()
main = start $
do f <- frame [ text := "Alarm Example" ]
p <- panel f []
en <- genericWidget p (Alarm "My alarm" $ Minutes 117)
b >= print ]
set f [ layout := container p $ row 10 [ widget en, widget b ] ]
The three italicized lines are the boilerplate needed to convert the Alarm type into widgets. Derive is a Template Haskell function which derives instances for the two type classes Data and Typeable. In this case we derive instances for the two data types Minutes and Alarm. We also needs to specify that Alarm and Minutes can be turned into widgets. That is done by the two instance declarations. The rest is similar to the previous example.
And the resulting GUI:
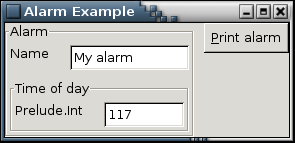
Specializing Alarm
Presenting time of day as minutes is not particular user friendly. However it is convenient to model it as such. Thus we would like to present the minutes differently to the user, as they are stored in the model. WxGeneric supports this:
{-# LANGUAGE FlexibleInstances, MultiParamTypeClasses
, TemplateHaskell, UndecidableInstances #-}
module AlarmSpecialized where
import Graphics.UI.WxGeneric
import Graphics.UI.SybWidget.MySYB
import Graphics.UI.WX
import Graphics.UI.WXCore
import Control.Monad
data Minutes = Minutes Int deriving (Show, Eq)
data Alarm = Alarm { name :: String
, timeOfDay :: Minutes
} deriving (Show, Eq)
$(derive [''Minutes,''Alarm])
instance WxGen Alarm
instance WxGen Minutes where
mkWid m' = toOuter (valuedCompose helper)
where helper p =
do changeVar <- varCreate (return ())
hours <- hslider p True 0 23 [ selection := fst $ minutes2Clock m' ]
minutes <- hslider p True 0 23 [ selection := snd $ minutes2Clock m' ]
let setChangeVar x = do set hours [ on command := x ]
set minutes [ on command := x ]
lay = grid 10 10 [ [ label "Hours: ", fill $ widget hours ]
, [ label "Minutes: ", fill $ widget minutes ] ]
getVal = liftM2 clock2Minutes (get hours selection) (get minutes selection)
setVal ys = do let (h, m) = minutes2Clock ys
set hours [selection := h]
set minutes [selection := m]
return ( lay, getVal, setVal
, varGet changeVar, setChangeVar
)
minutes2Clock (Minutes m) = (m `div` 60, m `mod` 60)
clock2Minutes h m = Minutes (60*h + m)
main :: IO ()
main = start $
do f <- frame [ text := "Alarm Specialized Example" ]
p <- panel f []
en <- genericWidget p (Alarm "My alarm" $ Minutes 117)
b >= print ]
set f [ layout := container p $ row 10 [ fill $ widget en, widget b ]
, size := Size 550 165 ]
The italicized code show the interesting lines. These lines specifies how to present the Minutes type to the user. It is done by making Minutes an instance of WxGen. We use two WxGeneric functions to help us – toOuter and valuedCompose. valuedCompose uses the helper function, which must return a 5-tuple consisting of:
- Layout
- a get value action
- a set value action
- a get change listener action
- a set change listener action
the rest of the code should be familiar.
And the resulting GUI:
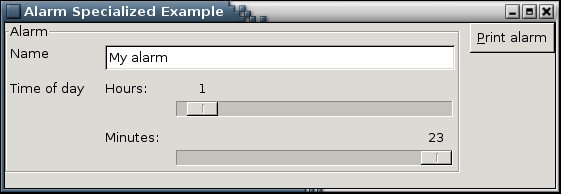
The code has blown up in size, and you may think that this do not free you from a lot of work as compared to making the GUI directly in WxHaskell. However, we can reuse the specialization of the Alarm type in other data types. For example if we have big data type Foo, which includes the Alarm type, we just need to make sure that the Alarm WxGen-instance is in scope and it is automatically used when turning Foo into a widget.
Also the specialization can be made more general. We can make a WxGen instance for all lists. Indeed, the list instance is already included in the distribution of WxGeneric.
Modeling Alarm using a data type
Specializing the Alarm type as done in the last section may seem a little troublesome. And indeed there is another way:
{-# LANGUAGE FlexibleInstances, MultiParamTypeClasses
, TemplateHaskell, UndecidableInstances #-}
module AlarmMapValue where
import Graphics.UI.WxGeneric
import Graphics.UI.SybWidget.MySYB
import Graphics.UI.WX
import Graphics.UI.WXCore
data Minutes = Minutes Int deriving (Show, Eq)
data Alarm = Alarm { name :: String
, timeOfDay :: Minutes
} deriving (Show, Eq)
data UserTime = UserTime { hour :: Int
, minute :: Int
} deriving (Show, Eq)
$(derive [''Minutes,''UserTime,''Alarm])
instance WxGen UserTime
instance WxGen Alarm
instance WxGen Minutes where
mkWid m' =
let minutes2UserTime (Minutes m) = UserTime (m `div` 60) (m `mod` 60)
userTime2Minutes (UserTime h m) = Minutes (60*h + m)
in mapValue userTime2Minutes (const minutes2UserTime) (mkWid (minutes2UserTime m'))
main :: IO ()
main = start $
do f <- frame [ text := "Alarm Map Value" ]
p <- panel f []
en <- genericWidget p (Alarm "My alarm" $ Minutes 117)
b >= print ]
set f [ layout := container p $ row 10 [ widget en, widget b ]
, size := Size 275 165 ]
In stead of modeling the interface using WxHaskell, toOuter and valuedCompose, we model it by another data type (UserTime). In the Minutes instance of WxGen we then describe how to translate between UserTime and Minutes.
And the resulting GUI:
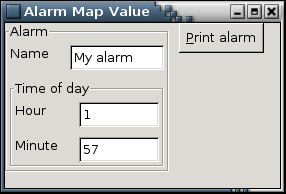
Your Turn
Now it is your turn to play around with WxGeneric and maybe integrate WxGeneric into some of your WxHaskell projects. You will properly find that WxGeneric’s on-line available Haddock docs are useful. I would love to get feedback about your experiences.
